
MapReduce深入解析
MapReduce必备原理解析
分布式计算框架
MapReduce
1、概念
MapReduce是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为Map和Reduce两个阶段的编程模型。(这句话记住了是可以用来装逼的)
2、执行流程
MapReduce程序执行图。
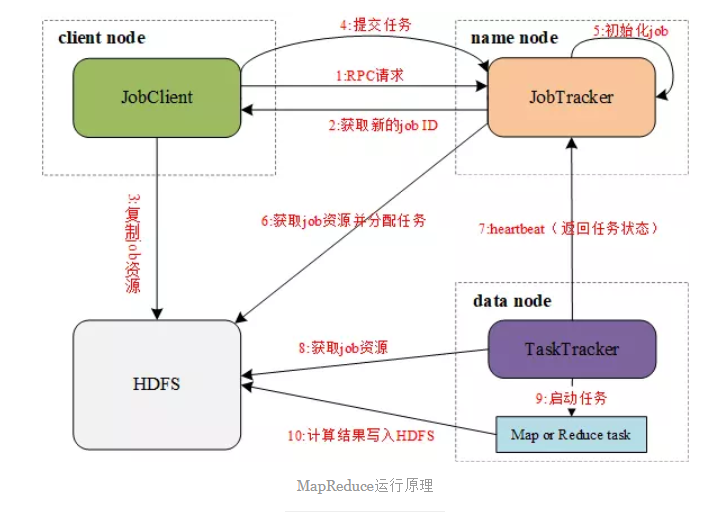
1. JobClient:运行于client node,负责将MapReduce程序打成Jar包存储到HDFS,并把Jar包的路径提交到Jobtracker,由Jobtracker进行任务的分配和监控。
2. JobTracker:运行于name node,负责接收JobClient提交的Job,调度Job的每一个子task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
3. TaskTracker:运行于data node,负责主动与JobTracker通信,接收作业,并直接执行每一个任务。
4. HDFS:用来与其它实体间共享作业文件。
MapReduce作业流程
1、JobClient通过RPC协议向JobTracker请求一个新应用的ID,用于MapReduce作业的ID
2、JobTracker检查作业的输出说明。例如,如果没有指定输出目录或目录已存在,作业就不提交,错误抛回给JobClient,否则,返回新的作业ID给JobClient
3、JobClient将作业所需的资源(包括作业JAR文件、配置文件和计算所得得输入分片)复制到以作业ID命名的HDFS文件夹中
4、JobClient通过submitApplication()提交作业
5、JobTracker收到调用它的submitApplication()消息后,进行任务初始化
6、JobTracker读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个TaskTracker
7、TaskTracker通过心跳机制领取任务(任务的描述信息)
8、TaskTracker读取HDFS上的作业资源(JAR包、配置文件等)
9、TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
10、TaskTracker将Reduce结果写入到HDFS当中
3、工作原理

4、Map任务处理
1、读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数
2、重写map(),对第一步产生的<k,v>进行处理,转换为新的<k,v>输出
3、对输出的key、value进行分区
4、对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中
5、(可选) 对分组后的数据进行归约
5、Reduce任务处理
1、多个map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点上
2、对多个map的输出进行合并、排序。
3、重写reduce函数实现自己的逻辑,对输入的key、value处理,转换成新的key、value输出
4、把reduce的输出保存到文件中




{kind=link}