
数据质量管理
数据质量是如何管理的?
数据质量管理
概述
数据质量的高低代表了该数据满足数据消费者期望的程度,这种程度基于他们对数据的使用预期。数据质量必须是可测量的,把测量的结果转化为可以理解的和可重复的数字,使我们能够在不同对象之间和跨越不同时间进行比较。
数据质量管理 是通过计划、实施和控制活动,运用质量管理技术度量、评估、改进和保证数据的恰当使用。
数据质量产生的根本原因
源系统: 源系统的数据结构发生变化,这是常有的事,数据仓库只是数据存储中心,而源系统的改变会造成数据仓库中数据质量发生变化
ETL: 源系统业务流程发生了变更
业务需求:
- 源系统数据录入错误或者延迟
- 源系统随着时间的推移,数据发生了演变
- 需求不明确或者满足不了客户需求
- ETL映射规则错误
- ETL程序错误
- 数据没有及时到达或者依赖关系错误
- 源系统的业务数据与业务需求发生冲突
数据质量面临的挑战
数据的污染是在数据仓库中处理的,延伸出去就形成了专业的数据治理,但是数据的污染却在数据仓库之外发生的,所有必须要清楚数据的污染源有哪些:
系统转换: 源系统的系统升级、转换、迁移是数据污染的重要原因
数据老化: 在经历一代又一代的系统升级、转换、迁移,历史数据往往无法满足当时时间的业务需求
复杂的系统集成: 源系统种类繁多,关系日渐复杂,出现污染数据的可能性越来越大
拙劣的数据库设计: 坚持实体完整性和参考完整性规则可以防止一些数据污染,但是目前数据仓库存在两种观点:注重模型、注重集市,围绕业务进行数据库设计,这两种观点与传统的十大主题设计存在矛盾点。
数据输入的不完整性: 源系统的数据输入是数据污染的主要来源,信息输入错误会给数据仓库模型建立造成很大的压力
缺乏数据治理相关的政策: 如果一个公司对数据质量没有明确的相关政策,那么他的数据质量不可能得到保证
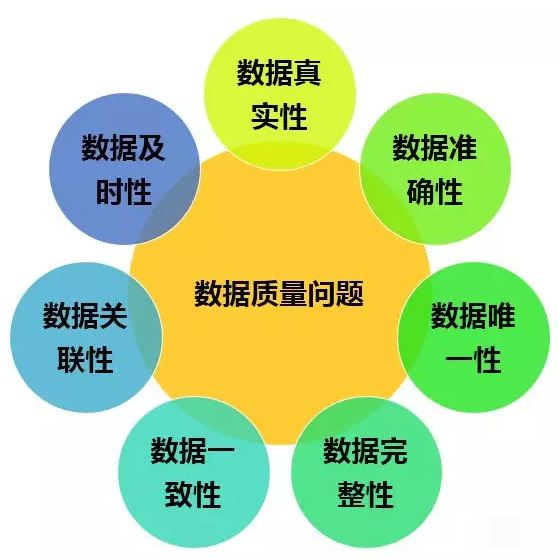
数据质量的指标
- 准确性
准确性要求数据能够正确描述客观世界。比如某用户姓名拼音mu chen错误的录入成了muc hen,就应该弹出警告语;
- 唯一性(视情况而定)
唯一性要求数据不能被重复录入,或者不能有两个几乎相同的关系。比如张三李四在不同业务环境下分别建立了近乎相同的关系,这时应将这两个关系合并;
- 完整性
完整性要求进行数据搜集时,需求数据的被描述程度要高。比如一个用户的购买记录中,必然要有支付金额这个属性;规则验证。
- 一致性
一致性要求不同关系、或者同一关系不同字段的数据意义不发生冲突。
比如某关系中昨天存货量字段+当天进货量字段-当天销售量字段等于当天存货量就可能是数据质量有问题;
- 及时性
及时性要求数据库系统中的数据”保鲜”。比如当天的购买记录当天就要入库;
- 统一性
统一性要求数据格式统一。比如nike这个品牌,不能有的字段描述为”耐克”,而有的字段又是”奈克”;
数据质量管理的方法论
在数据治理方面,不论是国际的还是国内的,我们能找到很多数据治理成熟度评估模型这样的理论框架,作为企业实施的指引。而说到数据质量管理的方法论,其实业内还没有一套科学、完整的数据质量管理的体系。很多企业对数据质量的重视程度还不够,即使部分企业在朝着这个方向努力,也是摸着石头过河。
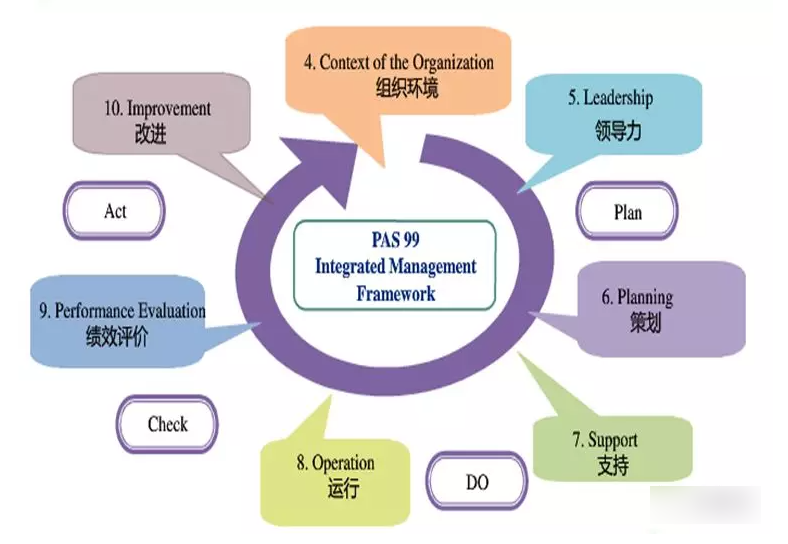
下图是ISO9001基于PDCA的质量管理核心思想,其重点强调
以客户为关注焦点、领导作用、全员参与、过程方法、持续改进、循证决策和关系管理。
数据质量监控
数据质量监控可以分为数据质量的事前预防控制、事中过程控制和事后监督控制:

数据质量问题的预防控制最有效的方法就是找出发生数据质量问题的根本原因并采取相关的策略进行解决。
1)确定根本原因:确定引起数据质量问题的相关因素,并区分它们的优先次序,以及为解决这些问题形成具体的建议。
2)制定和实施改进方案:最终确定关于行动的具体建议和措施,基于这些建议制定并且执行提高方案,预防未来数据质量问题的发生。






{kind=link}